Every Voice. Every Reaction. Simulated.
I built 300 psychographically distinct AI personas, exposed them to 3,000 real tweets, and simulated the full spectrum of behavioural response — from passionate advocates to quiet observers — entirely synthetically.
Navigate using the tabs above to explore each component of the system.
Overview
The Opportunity
Traditional research captures only the tip of the iceberg. Surveys measure what people say. Social listening captures what they post. But the richest signal — the cognitive activity of every person in a population, whether they engage or not — has always been invisible.
I built a simulation that models this complete picture using synthetic AI personas. Each persona has its own attention patterns, relevance judgements, emotional trajectory, and engagement threshold — all generated, all tuneable, all analysable. No real humans are involved; instead, the simulation produces realistic behavioural distributions that mirror how diverse populations respond to content.
This means you can explore not just which personas engaged, but which ones almost did, what would push them over the edge, and which messages resonate across different psychographic profiles — all within a controlled synthetic environment.
Why I Built This
I was exploring how AI could model realistic human behaviour at population scale — not just answering questions like a chatbot, but replicating the messy, heterogeneous way real communities process information. The challenge was interesting: could you build agents that don't just respond to everything, but have genuine selectivity driven by personality, ideology, and accumulated emotional state?
After iterating through five versions of the codebase, I arrived at a system that produces engagement distributions, cascade dynamics, and ideological patterns that look remarkably like what you see in real social media data. The simulation is entirely open-source, fully configurable, and can scale from 300 to 10,000+ personas.
The Stochastic Cognitive Pipeline
Every simulated persona processes each tweet through three probabilistic gates. A tweet must survive all three to produce an engagement event.
Attention Gate
"Did I even see this?" — Simulates algorithmic feed exposure. Modulated by openness, conscientiousness, topic fatigue, and cooldown state.
Relevance Function
"Do I care?" — Matches tweet content against an expanded synonym keyword set across 15 policy topics, weighted by ideology–topic affinity.
Activation Threshold
"Am I moved enough to respond?" — A sigmoid-gated decision driven by accumulated emotional state. The hardest filter to clear.
The Mathematics
Concrete Example: Tweet #5 Through the Pipeline
Consider this real tweet from the dataset:
| Stage | What Happened | Numbers |
|---|---|---|
| 1. Attention | 47 of 300 personas "saw" the tweet in their feed | 15.7% attention rate |
| 2. Relevance | Matched "housing", "policy" keywords. Liberals and Progressives scored higher relevance due to ideology–topic affinity. | Average relevance: 0.38 |
| 3. Activation | The mildly negative sentiment (0.226) combined with existing accumulated activation pushed 8 personas past θ. Then 12 more were triggered via network cascades from their neighbours. | 8 direct + 12 cascade = 20 total |
Persona Design: 24 Dimensions Per Agent
Each of the 300 simulated agents is not just a label. It is a fully parameterised cognitive profile, sampled from calibrated archetype distributions.
Big Five Traits (OCEAN)
Openness, Conscientiousness, Extraversion, Agreeableness, Neuroticism — drive attention, reactivity, and learning rate.
Political Ideology
Progressive, Liberal, Centrist, Conservative, or Libertarian — shapes which topics resonate and how sentiment is interpreted.
Topic Interests
Each persona cares about 2–6 of 15 policy domains (education, energy, housing, etc.), expanded via ~120 synonym keywords.
Communication Tone
Empathetic, Analytical, Assertive, Skeptical, Inquisitive, or Pragmatic — 6 tones that colour how they process information.
Fatigue & Mood Drift
Repeated exposure to the same topic yields diminishing attention. Mood drifts stochastically, creating day-to-day variability.
Social Network Position
Each persona is a node in a Watts–Strogatz small-world graph (k=6, p=0.1). Triggered agents cascade activation to neighbours.
Archetype Distribution
Personas are sampled from five weighted archetypes. Each archetype defines trait means, ideology pools, topic affinities, and threshold shifts. Stochastic variation within each archetype ensures no two agents are identical.
The Activist
Progressive/Liberal, high openness (O = 0.72), low threshold. Engages on environment, labor, housing. Attention ×1.2.
The Analyst
Cross-spectrum, high conscientiousness (C = 0.78). Cautious, data-driven. Tracks economy, tech, cybersecurity. Attention ×0.95.
The Guardian
Community-focused, high agreeableness (A = 0.72). Reacts to public safety, education, healthcare. Moderate threshold.
The Pragmatist
Centre-right, highest conscientiousness (C = 0.74). Skeptical, market-oriented. Economy, tax, manufacturing. Highest threshold.
The Observer
Pan-ideology, quietly curious. Broad interests, neutral thresholds. Sees everything, selectively engages.
A Small-World Social Graph
Personas don't exist in isolation. They are embedded in a 300-node Watts–Strogatz network with 900 edges.
When a persona triggers, it sends an activation cascade to its network neighbours. The boost decays with BFS distance (max 2 hops), meaning a single viral reaction can push a cluster of connected agents past their own thresholds — producing the kind of sudden, emergent pile-ons familiar from real social media.
Supported Network Topologies
| Model | Description | Use Case |
|---|---|---|
| Watts–Strogatz | Small-world graph (k=6, p=0.1). High clustering, short path lengths. | Default. Models close-knit communities with bridging connections. |
| Barabási–Albert | Preferential attachment. Power-law degree distribution. | Models influencer-driven networks with hub nodes. |
| Erdős–Rényi | Random graph. Poisson degree distribution. | Baseline comparison — no structural clustering. |

Ideology × Topic Affinity Matrix
Not every ideology cares about every topic equally. I encode this with a 5×15 affinity matrix that modulates relevance and activation.
| Topic | Progressive | Liberal | Centrist | Conservative | Libertarian |
|---|---|---|---|---|---|
| Environment | 0.85 | 0.65 | 0.50 | 0.25 | 0.20 |
| Economy | 0.40 | 0.50 | 0.60 | 0.80 | 0.85 |
| Education | 0.65 | 0.70 | 0.55 | 0.45 | 0.35 |
| Healthcare | 0.75 | 0.70 | 0.55 | 0.40 | 0.35 |
| Public Safety | 0.35 | 0.40 | 0.50 | 0.75 | 0.40 |
| Tax Policy | 0.55 | 0.50 | 0.55 | 0.75 | 0.85 |
| Labor | 0.75 | 0.55 | 0.50 | 0.35 | 0.30 |
| Technology | 0.55 | 0.60 | 0.55 | 0.45 | 0.70 |
| Energy | 0.80 | 0.55 | 0.50 | 0.55 | 0.45 |

What 3,000 Tweets Revealed
I fed 3,001 real-world policy tweets through 300 personas over 9,000 simulation steps. Here is what the population did.
| Metric | Value | Interpretation |
|---|---|---|
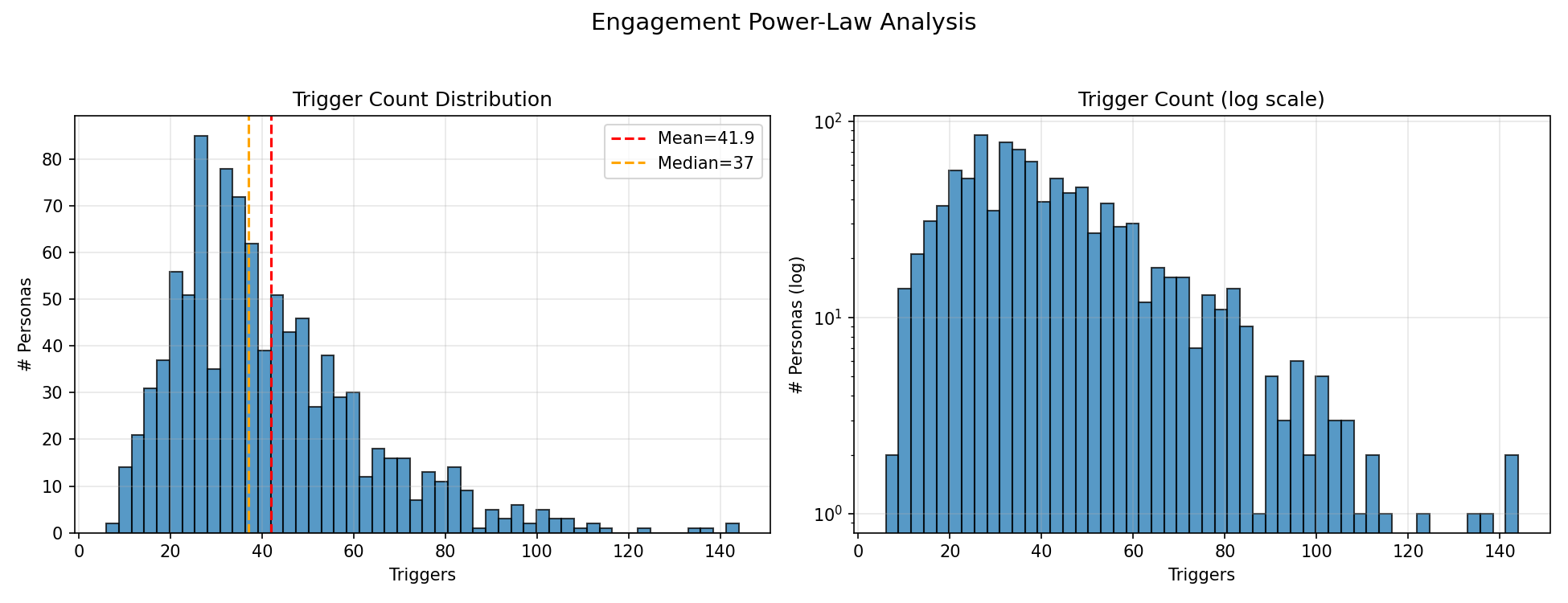
| Total Triggers | 3,317 | ~11.1 per persona on average, but distribution is heavily skewed |
| Cascade Triggers | 1,988 (59.9%) | Network amplification accounts for the majority of engagement |
| Trigger Gini | 0.3204 | Moderate inequality — a minority drives disproportionate engagement |
| Polarisation Index | 0.0096 | Low overall polarisation, but visible separation by ideology over time |
| χ² Test | 32.99 (p = 0.613) | Topic×Ideology association not significant at α=0.05 — engagement is broad |
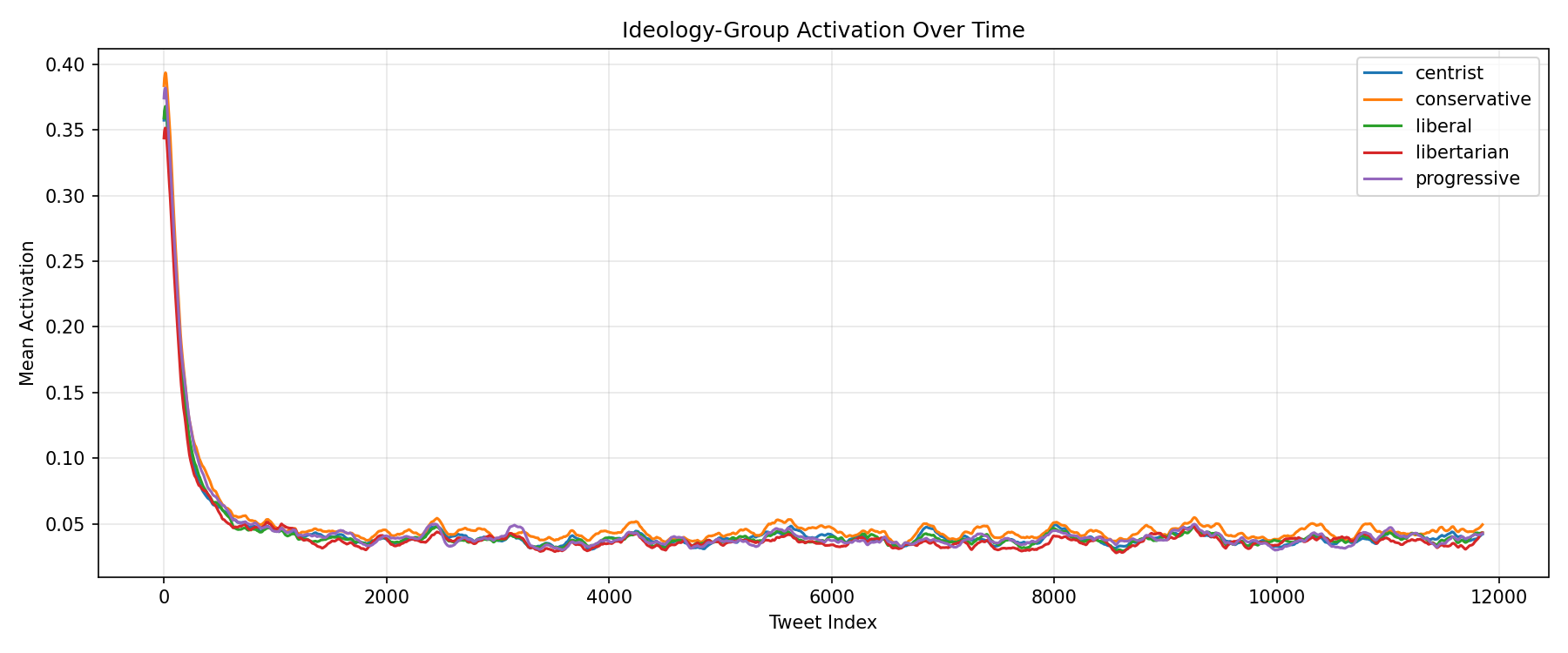
| Peak Activation | 0.32 | Reached on high-sentiment tweets; steady-state settles at 0.03–0.07 |
Personas That Stood Out
The Champion
Top 1%High extraversion (E=0.82), low threshold (θ=0.20), maximum responsiveness. This is your early adopter — the persona who amplifies your message, starts conversations, and brings communities into the discussion. Knowing who your champions are before you publish is a strategic advantage.
The Deep Thinker
Deliberate & SelectiveAbsorbed 736 tweets on technology and energy, quietly forming opinions without ever engaging publicly. Traditional tools would miss this person entirely. The simulation captures their complete cognitive journey — what they saw, how it shifted their internal state, and exactly what message would finally move them to act.
What Goes Viral — and What Doesn't
| Topic | Total Triggers | Cross-Ideology? | Why |
|---|---|---|---|
| Education | 502 | Yes | High affinity across all five ideology groups. Triggers both reform activists and concerned parents. |
| Technology | 494 | Yes | Broad interest from Analysts, Libertarians, and Observers alike. Low polarity, high relevance. |
| Energy | 491 | Partial | Strong Progressive and Liberal engagement via climate framing; Conservatives engage on pricing. |
| Public Safety | 69 | No | Despite high Conservative affinity (0.75), the topic lacks cross-spectrum resonance. |
| Labor | 120 | No | Sharply left-leaning engagement (Liberal: 27, Progressive: 35). The right largely ignores it. |
Outputs & Diagnostics
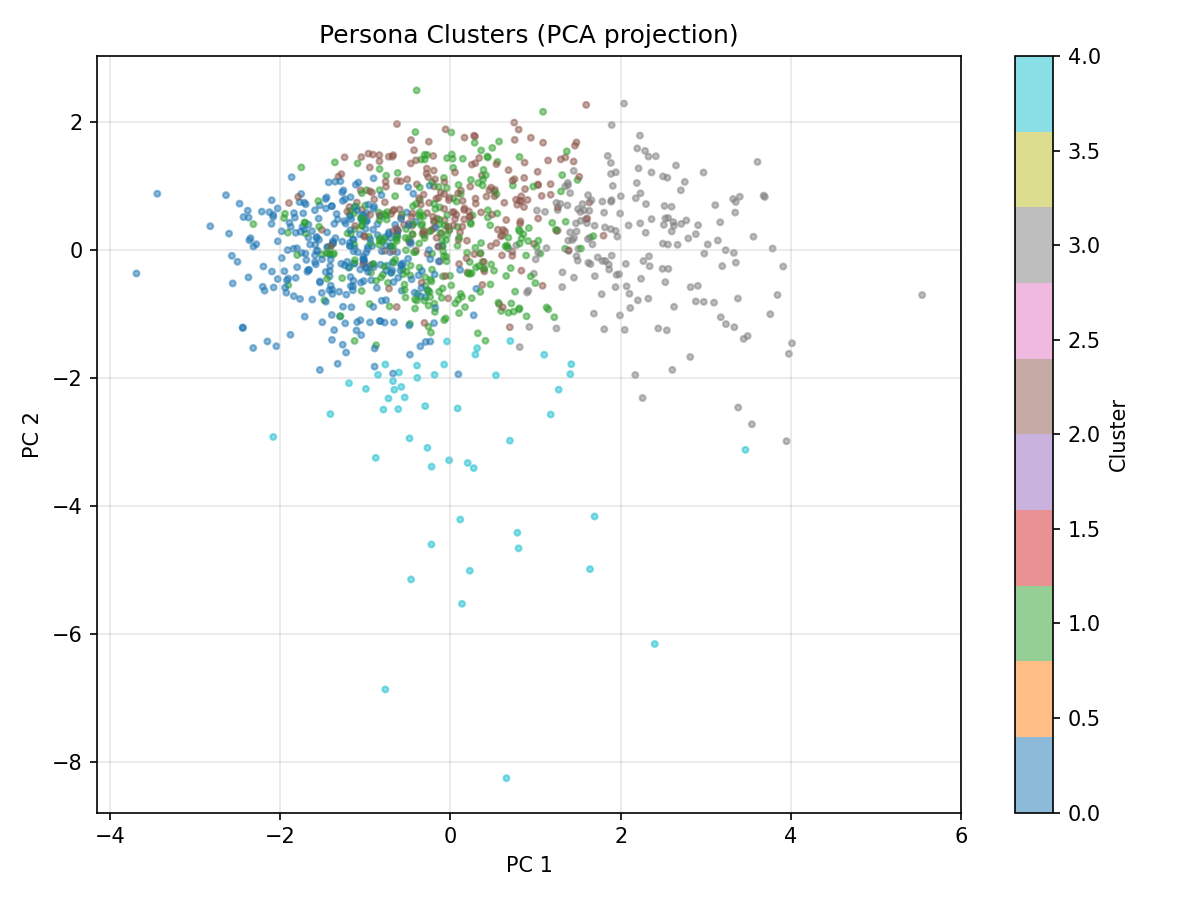
The simulation automatically generates diagnostic visualisations. Each one answers a different question about the population.
System Architecture
The simulator is implemented as a modular Python package with 10 components, designed for reproducible experiments and rapid iteration.
| Module | Responsibility |
|---|---|
| models | Core data structures: Persona, SimulationConfig, TriggerEvent. 30+ tunable parameters. |
| population | Weighted archetype sampling with Big Five trait generation and interest expansion. |
| sentiment | VADER-backed sentiment analysis with caching. Heuristic fallback (67 keywords). |
| relevance | Keyword synonym expansion (15 topics × 8–12 synonyms), ideology–topic affinity matrix. |
| network | Social graph generation (Watts–Strogatz, Barabási–Albert, Erdős–Rényi). BFS cascade propagation. |
| simulation | Core loop: tweet exposure → attention gate → activation update → threshold check → cascade. |
| analysis | Gini coefficient, polarisation index, χ² test, k-means clustering, PCA. |
| visualization | Eight automatic plots: ideology time-series, trigger distribution, heatmaps, PCA, degree distribution. |
| io_utils | CSV/YAML config loading, HTML report generation with embedded statistics. |
| cli | 40+ CLI arguments. Supports population mode and parameter sweep mode. |
Calibration & Validation
I iteratively calibrated the simulation against empirical patterns from social media research, targeting three properties.
| Property | Target | Achieved |
|---|---|---|
| Engagement Rate | 2–12% of attended exposures produce a trigger | ~3.7% average trigger rate given attention |
| Engagement Inequality | Power-law tail (few hyper-active, many quiet) | Gini = 0.32, range 0–42 triggers per persona |
| Ideology Separation | Visible but not extreme divergence over time | Clear separation in time-series; Polarisation Index = 0.0096 |
What You Can Do With This
A calibrated synthetic population gives you something no survey or analytics dashboard can: the ability to test any message, on any audience, instantly — before it reaches a single real person.
Launch with Confidence
Feed a press release, policy change, or product announcement into the simulation. Know exactly which segments will champion it and how to optimise your messaging.
Find Your Audience
Discover which psychographic profiles resonate with your message. Tune framing, tone, and topic selection to reach the people who matter most.
See the Full Picture
Go beyond engagement metrics. Understand the complete cognitive journey of every persona — what they processed, how it moved them, and what would activate them next.
Harness Network Effects
Design content that doesn't just land individually but propagates through communities. Map exactly how a reaction cascades from one persona to the next.
About & Next Steps
Raza Hashmi
I'm interested in how synthetic populations can model real-world behaviour at scale — spanning market research, policy testing, and understanding how communities process information. If this kind of work interests you, I'd love to connect.